
Peut-on quantifier la pertinence des sondages ?
par Tom Roud
mercredi 18 avril 2007
On a beaucoup parlé des « redressements » sur les sondages de premier tour. Pourtant, lorsqu’on se penche sur les sondages sur le deuxième tour, on voit également certaines bizarreries. Sur le site d’Ipsos, on peut lire que la marge d’erreur des sondages présidentiels actuels est d’environ 3 à 4 points. Qu’est-ce que cela signifie ? L’observation des évolutions des sondages sur le site IPSOS est-elle compatible avec cette marge d’erreur ?
Tout sondage, toute mesure sur un échantillon statistique comporte ce
qu’on appelle une marge d’erreur. Celle-ci est une propriété
intrinsèque à la mesure. Il est impossible
de faire des statistiques vraiment fiables sur des petits nombres : si on fait
deux fois la même mesure sur
le même ensemble (la même photographie
comme disent les sondeurs), il est relativement peu probable de trouver deux
fois le même résultat à cause de cette marge d’erreur intrinsèque. Différentes
enquêtes, faites sur le même échantillon au même moment, vont donner des
résultats différents. Si on fait de nombreuses fois cette mesure, on va voir que
les résultats s’échelonnent autour d’une valeur moyenne, sur un intervalle dont
la grandeur est de l’ordre de cette marge d’erreur. Donc théoriquement, si on
sonde une population votant à 53% pour un candidat, la plupart des résultats des
sondages devraient s’échelonner entre 50% et 56% environ. Mais le fait
important est que même si toutes les enquêtes sont faites parfaitement, il y
aura toujours des sondages qui devraient donner des écarts significatifs (pour
les médias, c’est-à-dire au moins de l’ordre de 2%) entre la réalité et le
résultat des sondages.
Début mars, IPSOS a lancé un outil terrible : il s’agissait de fournir un sondage présidentiel par jour. Aujourd’hui, on a suffisamment de données pour pouvoir faire une petite étude statistique assez rudimentaire des données d’IPSOS (pour voir une étude similaire sur d’autres sondages et avec un protocole un peu différent, voir le billet original sur mon blog). Que se passe-t-il alors lorsque l’on compare ces différents sondages ? La marge d’erreur est de l’ordre de 1 sur la racine carrée de l’échantillon : on frise donc dans la plupart des sondages au second tour les 4% d’erreur ; dans les sondages IPSOS quotidiens on est un peu plus proche de 3%. D’un sondage à l’autre, on devrait donc voir une danse des courbes "explorant" ces 3-4% d’erreurs.
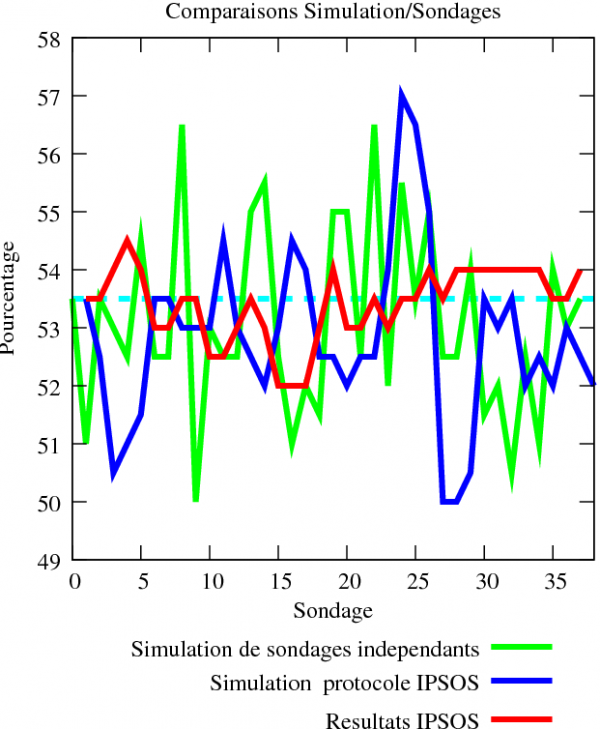
- Figure 1 : Comparaison IPSOS vs Simulations
- Cette figure décrit la comparaison de l’évolution des sondages quotidiens IPSOS avec des sondages simulés.

De fait,
je me suis amusé à faire quelques petites simulations par ordinateur, en
considérant 1 200 électeurs (pour me rapprocher de l’échantillon IPSOS), votant
au hasard soit entre Ségo, soit entre Sarko (et arrondissant au demi-entier le
plus proche pour Sarko, déduisant par différence le score de Ségo). J’ai
considéré que l’opinion "réelle" était à 53.5% pour Sarko (en faisant la moyenne
des opinions sur ces 38 sondages). La courbe verte représente la simulation de 38 sondages
consécutifs indépendants sur la population. La courbe bleue représente la simulation de 38
sondages effectués avec ce que j’appelle "le protocole IPSOS", c’est-à-dire qu’on
sonde tous les jours un tiers du panel, et qu’on moyenne avec les résultats des
deux jours précédents. Enfin, la courbe rouge représente l’évolution des 38
sondages consécutifs IPSOS.
Rappelons-nous qu’ici l’opinion supposée est à 53.5 % (ligne bleu clair
pointillée). Le but de ces courbes est d’illustrer ce qu’on devrait voir
théoriquement pour un sondage avec une marge d’erreur d’environ 3%. On voit très
clairement que les intentions de votes sondées devraient fluctuer énormément
avec le temps et atteindre même 50-50 quelques fois. Par ailleurs, le protocole
IPSOS est potentiellement un nid à fluctuations : la marge d’erreur sur une
population de 300 personnes est beaucoup plus grande (quasiment 6%), et si on a
une grosse fluctuation statistique dans un sens ou dans l’autre, le résultat
peut se maintenir trois jours (courbe bleue foncée, autour des sondages 3,
sondages 22, sondages 26). Or, on voit à l’oeil nu que les courbes "réelles" varient
extrêmement peu d’un sondage à l’autre en comparaison,
elles sont beaucoup trop lissées : la
semaine dernière, il y a même eu une série de 7 sondages donnant 54%. Il est
extrêmement peu plausible qu’un sondage donne 7 fois consécutivement le même
résultat. Imaginez que vous lanciez 7 fois de
suite un dé, et que vous tombiez sept fois de suite sur 6. Croiriez-vous au bon
équilibrage du dé ? Les sondeurs me diraient qu’ils ont une façon de
corriger, pour lisser les courbes. C’est tout bonnement impossible : encore une
fois, l’erreur est intrinsèque au processus même de la mesure (sinon, j’engage
les sondeurs à immédiatement soumettre leur technique à Nature, cela peut
intéresser pas mal de monde) !
Essayons maintenant de quantifier un peu plus tout cela.
Dans
un premier temps, j’ai fait travailler ma cellule de sondage virtuelle
d’arrache-pied pour lui faire faire 100 000 sondages sur une population d’environ 700 individus à 52%
sarkozystes, pour illustrer le gros problème qui se pose en particulier pour prédire l’ordre d’arrivée lorsque
à la fois les échantillons et les écarts entre les candidats sont petits. La courbe ci-contre donne le
pourcentage de sondages donnant un résultat donné (cette fois j’ai arrondi au
point ; on retrouve évidemment une gaussienne). Notez tout d’abord que tous les résultats à l’intérieur de la mage d’erreur (la largeur de la gaussienne) ne sont pas équiprobables : le pic est autour du bon résultat.
- Figure 2 : Gaussienne théorique des sondages
On voit ensuite très clairement qu’alors
à peine 20% des sondages donnent le "bon" résultat, qu’au contraire 40% des
sondages se trompent de plus de deux points, et 20% donnent Sarko à 50% ou
moins. On voit exactement le même effet sur les courbes plus haut, et c’est ce
qui explique théoriquement les fluctuations dans les sondages simulés. Cela
relativise considérablement les disours du genre "Ségo s’écroule" quand elle
perd 1 point par rapport au sondage précédent. De plus, on voit que dans une
période où l’opinion est à 52-48, 1 sondage sur 5 donne carrément le mauvais
résultat, tandis qu’un autre sondage sur 5 donne une victoire à plates coutures
du bon candidat. Le tout au même moment, sur le même échantillon, je vous le
rappelle ! Evidemment, cela ferait désordre si les instituts de sondage
donnaient des résultats si contradictoires...
Dans un second temps, j’ai essayé de quantifier le degré de "lissage" des
courbes. Reprenons l’image du dé : il paraît très peu probable en lançant un dé
7 fois de suite d’avoir 7 fois 6. Pourtant, cette séquence est en fait tout aussi
probable que n’importe quelle séquence ordonnée de 7 chiffres entre 1 et 6, mais si on considère les séquences desordonnées, elle devient en effet assez improbable. Peut-on faire la même chose pour les sondages ? Autrement dit, peut-on quantifier ce qu’est une série de sondages "typique" ?
Il s’agit de déterminer, de quantifier, la "plausibilité" d’une série de
sondages. Si les sondages sont un peu truqués, un peu cuisinés, un peu arrangés,
ils devraient normalement avoir des propriétés statistiques un peu biaisées.
Comme l’a fait très bien remarquer
FrédéricLN
sur son blog, si tous les sondages se plantent de la même façon et dans la
même direction, ce n’est pas qu’il y a erreur, mais un vrai biais. Ce qui a été
anormal en 2002 n’est pas que quelques sondages se soient trompés, mais bien
qu’aucun sondage n’ait jamais classé Le Pen devant Jospin (ce qui aurait dû
arriver statistiquement ... dans au moins un sondage sur deux, compte-tenu de la
faible différence entre leurs scores).
L’une des caractéristiques des sondages est, on l’a dit, que la marge d’erreur
effective semble beaucoup plus faible que la marge d’erreur statistique normale
(les fameux 3 pour cent). Qualitativement, on l’a vu, cela se traduit par le
fait que les courbes des sondages n’explorent pas assez le domaine autour de
leurs valeurs moyennes. Théoriquement, on devrait pouvoir regarder la
distribution de résultat autour des valeurs moyennes, et montrer qu’on a une
déviation de la distribution gaussienne. Le seul problème est que pour faire
cela, il faudrait avoir beaucoup, beaucoup de données pour faire de tels
sondages... sur les sondages ). J’ai fait le test dans des simulations : même
avec une quarantaine de sondages, on est encore assez loin de pouvoir récupérer
tout le profil de distribution gaussien, représenté plus haut. En revanche,
peut-être est-ce déjà suffisant pour avoir des informations sur certains
paramètres de la distribution...
A défaut de pouvoir tracer une jolie gaussienne, j’ai essayé de trouver un moyen de comparer l’évolution sur ces 38 sondages à une évolution qui serait "typique" d’un sondage. J’ai donc simulé 100 000 séries de 38 sondages sur 1200 personnes suivant le "protocole IPSOS", et j’ai essayé de caractériser certaines propriétés statistiques sur ces sondages, afin de voir si la courbe réelle partageait les caractéristiques "typiques" de sondages simulées. Pour caractériser le lissage des courbes, je me suis plus particulièrement intéressé à la distribution des scores minimaux et maximaux sur la série de sondages.
- Figure 3 : Distribution des minimas et maximas
Mon
hypothèse est que le score "réel" de Sarkozy est à 53.5 % (le pic des données
est à 54%, la moyenne étant à 53.4 - ce qui est à peu près cohérent). La courbe
bleue montre
la distribution de scores minima sur une série de 38 sondages, la courbe verte
montre la distribution de scores maxima sur la même série, la courbe rouge est
la distribution de résultats du sondage IPSOS. Ce que nous dit la courbe bleue,
c’est que, statistiquement, sur une série de 38 sondages centrés autour de 53.5%,
25% ont un score minimum de 51, 25% ont un score minimum de 50.5%. C’est
bien normal sachant que la marge d’erreur est d’environ 3%. De la même façon, la
courbe verte nous dit que dans 20% des séries de 38 sondages, le score du
candidat monte à 56 ou 56.5 %.
Examinons maintenant la courbe rouge. En réalité, le score minimum de Sarkozy
sur la série de 38 sondages est 52%, le score maximum, 54.5 %. On voit très bien
sur cette courbe que ces deux scores sont dans les queues de gaussiennes
respectives des distributions des scores maxima et minima. Plus précisément,
dans mes simulations, seulement 5% des sondages ont un score minimum supérieur
ou égal à 52 %, et à peine 1 % des sondages ont un score maximum inférieur ou
égal à 54.5%. Cela voudrait dire que le sondage réel est dans une zone
statistiquement insignifiante : si on fait le produit seulement 0.05% des
sondages réels ont des distributions similaires ! Si vous préférez, si on
refaisait cette série de 38 sondages plusieurs fois, théoriquement, plus de
99.95 % des sondages devraient monter plus haut ou descendre plus bas que ce qui
est effectivement observé. Admettons maintenant que je baisse ma tolérance d’un
demi-point : dans mes simulations, environ 20% des sondages ont un score minimum
supérieur ou égal à 51.5%, 7% des sondages ont un score maximum inférieur ou
égal à 55%, cela donne moins de 2 % des sondages avec des écarts maximum-minimum
similaires. Autrement dit, plus de 98% des sondages montent plus haut ou
descendent plus bas d’un demi-point. Cela reste assez faible et fait douter de la pertinence des méthodes des sondeurs.
Vous l’aurez noté dans ce petit exercice, ce qui rend la distribution improbable
n’est pas tant la distribution individuelle du minimum et du maximum (qui
sont ici en fait assez indépendants), mais le fait que les deux scores minima et
maxima soient simultanément respectivement grand et petit. Je me suis donc amusé
à représenter dans le graphique ci-contre le nombre de séries de sondages
aléatoires donnant à la fois un pourcentage maximum et un pourcentage minimum
donné. Sans surprise, on obtient une bosse à peu près gaussienne. La cote d’un
point est proportionnelle à
la
probabilité d’observer un sondage avec un couple maximum, minimum donné.
- Figure 4 : Représentation 3D de la plausibilité des sondages
La
flèche rouge indique la série actuelle IPSOS. Ce qui est intéressant est qu’on a
immédiatement un point de comparaison visuel avec toutes les autres séries de sondages : une région
à cote zéro est très improbable, tandis que les sondages en haut de la bosse,
s’ils sont individuellement improbables (exactement comme ma série
de lancers de dé) sont relativement beacoup plus probables. On voit très bien que les
sondages réels sont ... tout en bas de la bosse, dans une zone complètement
improbable.
En fait, on retrouve tout simplement l’effet décrit précédemment :
l’exploration
autour de la valeur moyenne est ridicule - avec un score "réel"
d’environ 53.5%,
le sondage descend au minimum à 52% et monte au maximum à 54.5%. Dans
une série 38 sondages, 30% des sondages devraient même descendre à 50%
ou en dessous et monter à plus de 57%. On a donc
en réalité dans les sondages IPSOS une marge d’erreur "effective" de 1
à 2% ici (à
comparer avec les 3-4% annoncés sur le site) ; cela correspondrait à une
population effective sondée d’au moins 2500 personnes. On parle
beaucoup
d’ajustements des scores au premier tour, mais à mon avis on voit très
bien sur
cet exemple que ces scores de deuxième tour semblent eux aussi très
arrangés,
malgré l’absence de vote Le Pen. Peut-être les sondeurs ont-ils des
superméthodes statistiques qu’ils nous cachent (pourquoi alors annoncer une
marge
d’erreur de 3% ?) : cette série de sondages est complètement conforme à
un score
de 53.5% de Sarkozy ; ce qui est juste très étrange c’est cette marge
d’erreur
complètement rabotée. Peut-être les échantillons ne sont-ils pas assez
variés
(après tout, peut-être les sondeurs ne sondent-ils réellement que 2500
personnes, toujours les mêmes - cela pourrait expliquer bien des
choses...).
Peut-être les sondeurs ont-ils aussi un flair extraordinaire qui leur
permet de
jauger en permanence l’opinion publique réelle. Peu importe ; dans tous
les cas,
il est clair qu’il manque quelque chose pour expliquer le résultat.
J’entends déjà les contre-arguments : et justement, la méthode des quotas ?
Deux raisons font que prendre en compte la méthode des quotas ne va pas changer
significativement l’absurdité de ces résultat :
La première raison est scientifique : supposons qu’une population se partageant
à 50-50 entre deux votes se divise en deux populations votant à 60-40 et 40-60.
Dans un sondage sans méthode des quotas, la marge d’erreur sera proportionnelle
à racine_carrée(0.5*(1-0.5)) = 0.5 (voir ici pour une explication de la formule ), dans l’autre cas, elle sera proportionnelle à
racine carrée(0.5*0.6*(1-0.6) + 0.5*0.4*(1-0.4)) = 0.489. Cela signifierait passer
d’une marge d’erreur de 3% à ... 2.9 % ! Si on va jusqu’à deux populations à
75-25 et 25-75, on arrive péniblement à 2.6% de marge d’erreur. Le gain de marge
d’erreur est bien trop faible pour expliquer la différence entre les sondages et
le simulations.
La seconde raison est méthodologique. Il est en fait bien connu depuis
plusieurs
années que la méthode des quotas... marche dans la pratique très mal.
Claire Durand, chercheuse en sociologie au Québec, a mené une étude des
sondages
français en 2002 dans une publication intitulée
Though the British Election Panel Study arrived at a good reconstitution of the 1992 vote using a random sample, the reconstitutions by pollsters using quota samples differed substantially from the actual vote.Notez que la méthode des quotas est dépassée sur cet exemple précis par une simple interrogation aléatoire. La raison est que les quotas sont trop restrictifs et fractionnent trop la population, ce qui fait que les sous-échantillons ont toutes les chances de ne pas être très représentatifs, et aussi entraînent des problèmes de "fraude" potentielle de la part des sondeurs : lorsque les sous-quotas sont petits, le sondeur peut-être tenté "d’inventer" des électeurs lorsqu’il n’arrive pas à avoir assez de données. Dans la suite, on apprend même qu’on sait depuis 1995 qu’ajuster les résultats en fonction des élections précédentes (ce que CSA dit faire aujourd’hui pour redresser - Roland Cayrol ayant même déploré que ces têtes de linottes d’électeur oublient ce qu’ils ont voté à l’élection précédente - in "Arrêt sur Images" sur les sondages) peut même dégrader l’estimation. La difficulté est d’autant plus grande qu’on ne sait pas forcément en France quelle élection utiliser pour cette reconstitution.
Bien que le "British Election Panel Study" ait permis une bonne reconstitution des résultats de 1992 en utilisant un échantillonage aléatoire, les reconstitutions des instituts par la méthode des quotas différaient substantiellement des résultats observés.
Tout cela n’explique néanmoins toujours pas pourquoi les courbes des sondages sont très lissées. Heureusement, Claire Durand dans son article nous éclaire :
One pollster, who requested anonymity, explained in this way the process by which he decides on published estimates : "The statistician provides me with estimates according to different adjustments (...). I look at the different columns and at the published estimates for the last week in order to figure out the most likely figure. Say a candidate had 2 percent the previous week and has 4 percent in most adjustments that week, I will put him at 3 percent. If he still has 4 percent in the next poll, then I will put him at 4 percent."Voilà en quelques phrases l’explication de nos fameuses courbes lissées et confirme mon hypothèse exprimée dans un billet précédent de mon blog. Ces petites corrections n’ont l’air de rien à première vue, mais d’un point de vue scientifique, c’est clairement injustifié. C’est en effet considérer toute variation a priori comme une fluctuation statistique. Or, on ne peut se débarrasser des fluctuations statistiques : comment alors les distinguer des évolutions ? Il faut donc potentiellement dans ce cas de figure au minimum deux sondages pour avoir le bon résultat. Imaginons qu’une fluctuation statistique aille dans le mauvais sens après une évolution effective : pour des sondages "classiques", il faudrait alors 3-4 sondages pour voir l’évolution réelle. Soit de 2 à 4 semaines de campagne. C’est aussi cet effet qui explique plus haut que dans mes simulations de protocole IPSOS, les grosses fluctuations se maintiennent asez longtemps. C’est donc à mon sens extrêmement grave de modifier ainsi les données brutes alors que les évolutions des sondages sont pile poil dans la marge d’erreur, car cela fausse complètement l’analyse des évolutions. Par ailleurs, ce genre de méthode est-il neutre politiquement, traite-t-on tous les candidats de la même façon ? N’y a-t-il pas par construction un effet "prime au gagnant" ... des semaines précédentes ?
Un sondeur, qui a demandé de conserver l’anonymat, explique ainsi la méthode employée pour traiter les données : "Le statisticien me livre des estimations après divers ajustements. Je regarde alors les différentes colonnes et les estimations publiées la semaine précédente afin de déterminer le chiffre le plus probable. Supposons qu’un candidat soit à 2 pour cent la semaine précédente, et 4 pour cents après estimations de cette semaine, je le mets alors à 3 pour cent. S’il a encore 4 pour cent au sondage suivant, je le mets alors à 4 pour cent.
Jules de diner’s room critiquait Schneidermann qui préconisait d’interdire purement et simplement les sondages, arguant notamment du fait qu’on a droit à l’information. Or, il apparaît que :
-
les données brutes, qui sont la véritable information, sont manifestement
pas inaccessibles alors qu’elles devraient l’être (voir sur mon blog
le
billet original sur l’article de Claire Durand, où elle explique les
bâtons dans les roues illégaux qu’on lui a mis pour accéder aux méthodes
des sondeurs) ;
-
par ailleurs, les sondeurs s’arrogent le droit (sous le contrôle de la
commission des sondages) de décider ce qui constitue une information d’une
fluctuation statistique, alors qu’ils n’ont aucun moyen de le faire.
Laissons la conclusion à Durand et al., ou plutôt à Jowell et al. :
One would be tempted to issue the same recommendation as Jowell et al. : "Our recommendation to pollsters and their clients, the mass media, is that they should invest in a program of methodological work as soon as possible. Sampling methods need to be improved, and the rather primitive methods of forecasting employed by the polls need to be supplemented by more sophisticated techniques that draw on the massive body of data about voting behavior and political attitudes that is freely available."Nous serions tentés de suggérer comme Jowell et al. : " Notre recommandation pour les instituts et leurs clients, les mass-media, serait de rapidement se lancer dans un programme de travail méthodologique. Les méthodes d’échantillonage doivent être améliorées, et les méthodes de prédiction plutôt primitives utilisées par les sondeurs doivent être accompagnées de techniques plus sophistiquées se basant sur les masses de données à propos des habitudes de votes et des attitudes politiques librement disponibles".